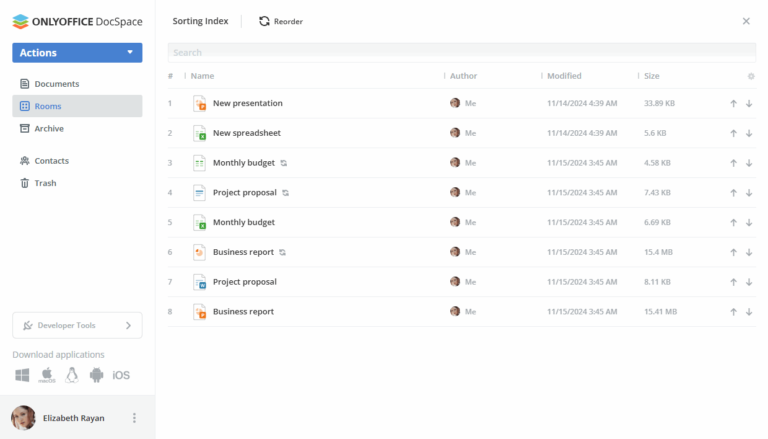
OCR stands for optical character recognition, and software of this type is designed to convert images, pictures, or scanned documents into editable and searchable text. Using it, you don’t need to manually type up documents as they are automatically transformed into machine-readable text format, which comes in handy in some situations and allows you to save time and effort. If you are looking for an easy-to-use but powerful OCR tool, there are both open-source and commercial options available for Linux users, ranging from Python libraries to professional SDKs. In this article, you will find the best open-source programs that you can use to transform whatever you have at hand, whether it be a photo or a scanned copy of a legal document, into editable text. 1. OCR Tools in ONLYOFFICE Docs If you often work with documents, spreadsheets, presentations, diagrams, and PDFs, ONLYOFFICE Docs might be an ideal choice for you as it combines reliable OCR capabilities and the functionality of a full-featured open-source office suite. Available as a self-hosted solution for Linux and Windows servers, which easily integrates into any web-based DMS, CMS, or file-sharing platform to enable real-time collaboration, the suite also provides a free desktop app, based on the same engine and compatible with any Linux distribution. In ONLYOFFICE Docs, OCR works in two ways so you can choose what works best for you. First of all, there is an OCR plugin in the built-in plugin marketplace. It doesn’t come preinstalled and requires manual installation, which involves a few clicks. After installation, the OCR plugin will allow you to recognize text in images and photos in PNG and JPG formats and insert the recognized text into your documents for further editing. ONLYOFFICE’s OCR plugin is based on Tesseract.js, a JavaScript library built on top of the Tesseract OCR engine, and provides support for more than 60 languages. Another way of using OCR in ONLYOFFICE Docs provides more opportunities and features as it involves artificial intelligence. The suite has a special plugin whose main purpose is to integrate all popular AI assistants and chatbots and use their capabilities for document editing tasks, such as text generation, translation, grammar and style correction, summarization, and more. Some modern AI models are specifically designed for OCR purposes, and you can even find some open-source LLMs tailored for optical character recognition. Such models can be added to the ONLYOFFICE AI plugin provided that you have a valid API key issued by the corresponding AI provider. When added, your IA model can recognize text from images in your document using the OCR option in the context menu. The biggest advantage of this AI-powered OCR integration is that you don’t have to use something by default and can convert images into editable text directly in your documents. You are free to choose from various AI models provided by companies and platforms you can trust, e.g. Mistral, Anthropic, Ollama, GPT4ALL, LocalAI and more, including custom models. 2. OCRmyPD OCRmyPDF is an open-source tool that recognizes text by adding an OCR text layer to PDF pages and making them suitable for search and copy/paste operations. In fact, the recognized text in your PDFs can’t be edited unless you open it in a PDF editor. What OCRmyPDF does is add new searchable text layers to scanned PDFs while keeping the original PDF formatting elements. The output result of the OCR conversion is a new searchable PDF/A file with optimized images. The tool uses the Tesseract OCR engine and easily handles files with thousands of pages. Another advantage is that it keeps your data private, allowing you to work with confidential files and PDF documents. As a command-line tool, OCRmyPDF requires knowledge of terminal commands but allows you to automate the optical character recognition process. 3. gImageReader gImageReader is a free and open-source OCR program developed as a user-friendly front-end for the Tesseract OCR engine. Due to its intuitive graphical user interface, Linux users can effortlessly extract text from their images, photos, scanned documents, and PDF files, making it easier to get editable text formats. When using this tool, you can manually select the required recognition area or rely on the automatic selection option. One of the advantages of gImageReader is its ability to process several files in one go, allowing you to deal with a large number of documents much faster. Apart from images and PDFs, gImageReader also supports hOCR, an open standard of data representation for formatted text obtained through OCR. For example, you can convert such files to PDF format. What else is worth mentioning is multilingual support — gImageReader is available in several languages in addition to English. 4. OCRFeeder OCRFeeder is an open-source OCR suite for the GNOME desktop environment. The tool comes with
Similar Posts
Shiba Inu Crypto Prediction 2025: Next Big Coin?
To make money, you can buy cryptocurrency, hold it until its value rises, and sell it…
Pandas: An open-source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for Python.
Are you looking to enhance your data analysis skills with Python? Look no further than Pandas!…
Top 3 Open Source Virtual Data Room (VDR) for Linux
A virtual data room, commonly known as VDR, is a feature that allows users to store,…
How to Use WordPress Contextual Help to Improve UX (5 Steps)
Chaosamran_Studio / stock.adobe.com In its most basic state, the WordPress dashboard might not seem like it…
Top IT Consulting Services – Boost Efficiency, Innovation & Growth!
During a conference in 2015, former Cisco CEO John Chambers made a grim prediction to an…
Build Your Website: A Beginner’s Guide in Simple Steps
Thinking about starting your own website but unsure where to begin? You’re not alone. Learning how…